The situation
A little while ago, I was faced with a database server that had run out of storage. It had been out in the world for awhile, and no one was watching it particularly closely. It was running on a deprecated version of SQL Server Express that limited it to 4gb per database.
I created a new instance of the database with the same schema in an upgraded version with cloud support for scaling and started loading and testing it, while manually babysitting the original one to clear out data often enough to keep the application up. I thought it was going pretty smoothly, but another engineer I work with – who doesn't ordinarily interact with databases - was frustrated: "Can't you just set it to limit each attribute to a certain number of rows?" he asked.

Unsatisfied with that, he asked if we could use "post-commit hooks" to do it. The look on my face…

Turns out he was suggesting we use a trigger to delete rows over a certain number for an attribute after insert. I rejected this idea, explaining that triggers were tricky.

It's a simplistic answer, but it’s based on my experience which has shown that DML triggers in databases are usually are the wrong way to solve a problem. There are a few other reasons to be careful about triggers generally:
- Triggers make debugging difficult and obscure what happens on an operation. They don't show up in your ORM and aren't called directly from code.
- They are more easily lost than other database objects; they aren't automatically included in a backup of the database in SQL Server and can be disabled.
- Performance can suffer, since they increase the number of transactions.
 Case in point: This is the database where I created the trigger. For some reason it doesn’t show up in the object explorer? Yes, I refreshed it.
Case in point: This is the database where I created the trigger. For some reason it doesn’t show up in the object explorer? Yes, I refreshed it.
Other people who are actually DBAs, and don't just play one in a pinch like me, have similar thoughts:
I'm not against triggers in all situations, I just think they have very limited use cases and shouldn't be applied to certain types of problems (like an under-resourced server).
Those are all kind of instinctual reasons though. My argument was that it would take longer to implement and test than the migration to an upgraded instance that was underway. This was true and I think it was reasonable, but it did bug me that my answer kind of sounded like the "wrong" response in this comic: XKCD Airfoil
{kind=link}
Especially because this engineer (who again, does not work in databases) responded with:
re: the trigger. I didn't see much danger in a trigger than wipes records x -> max by attrbute in the table… then again.. I have no idea what the schema for this db is. it could be all mixed in the same table or something wonderful. but if you're close on the database migration… cool.

Were my instincts about this wrong? His confidence struck me as the kind of solution you come up with after taking a DB101 course in college. Triggers seem like they will be super useful.
Although the schema is reasonable, the table we were discussing supports millions of records and very frequent insert load. Records with the same testnum are often inserted in quick succession, so I was worried about deadlocks.
I decided to do some testing with a local database and trigger at a similar scale to see.

Setting up a test
Here is the table I created, and the script to fill it with 2 million random rows:
CREATE Table TestEvent
(
Id int identity primary key,
TestNum nvarchar(450),
TestData nvarchar(50),
CreatedDate datetime
)
--Fill the table with 2mil records for random TestNum between 0-5000
DECLARE @Id int
SET @Id = 1
WHILE @Id != 2000000
BEGIN
INSERT INTO TestEvent VALUES (
floor(rand()\*5001),
CAST(@Id asnvarchar(10)),
DateAdd(day,floor(rand()\*-10),getdate())
)
SET @Id = @Id + 1
END
Alright, now we need to create a trigger that will delete the oldest records for any given test num over a given threshold of 50. Here is how I did that – there might be better ways, but keep in mind that "inserted" is a table. It's easy to write a trigger that will fail on bulk inserts (The Silent Bug I Find in Most Triggers - Brent Ozar).
CREATETRIGGER dbo.RemoveOldestRecords ON [dbo].TestEvent AFTER INSERT
AS
BEGIN
SET NOCOUNT ON
BEGIN
DELETE te From TestEvent te JOIN
(SELECT Id, TestNum
FROM
(
SELECTROW\_NUMBER()OVER (PARTITIONBY TestNum ORDERBY Id DESC)as RowNum, Id, TestNum
FROM TestEvent Where TestNum IN(Select TestNum From inserted)
) MinToKeep WHERE RowNum = 50) as InsertedMinIds
ON te.TestNum = InsertedMinIds.TestNum Where te.Id \< InsertedMinIds.Id
END
END
Well, that works slick with a single insert. To test, I found the count for records with a particular TestNum, looked up the 50th id, and then ran a single insert for the same TestNum. Afterward, the old 50th ID for the TestNum was deleted along with all greater Ids. I should mention, this has a CreatedDate column, but I'm using the Id. This makes sense with the system I was working on, even though they aren't synonymous in my generated data.
Baseline Performance
Lets disable the trigger and check the baseline performance for running thousands of inserts against the table as it exists. To do so, I'm using SQL QueryStress to run multiple iterations and threads against the database. It's a handy tool, since queries can perform very differently at scale than individually.
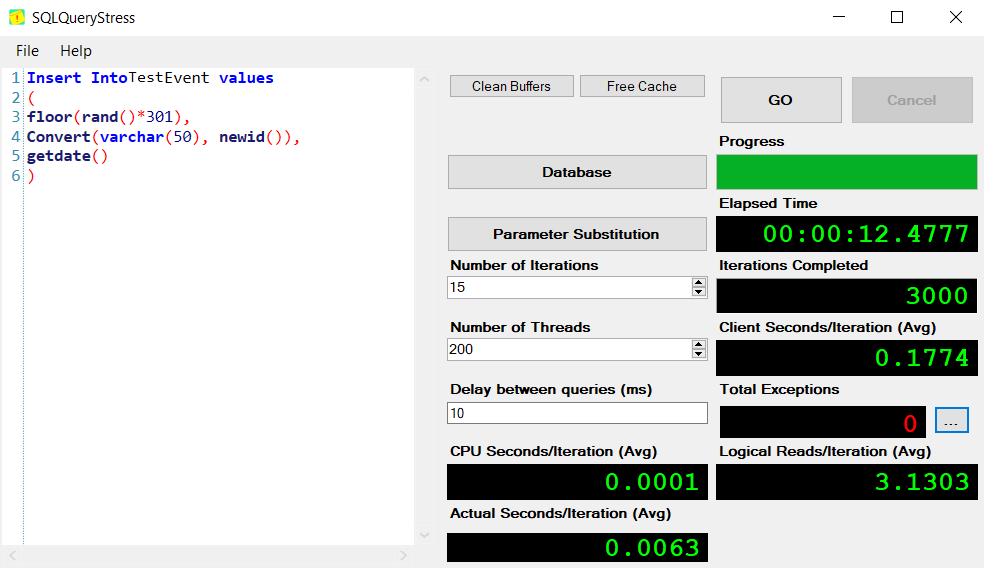
That was 3000 inserts (15 iterations across 200 threads) representing the range of TestNum from 1-300, and it completed in ~12.5 seconds with no exceptions.
Performance with Trigger
Now we'll enable the trigger and try the same thing.
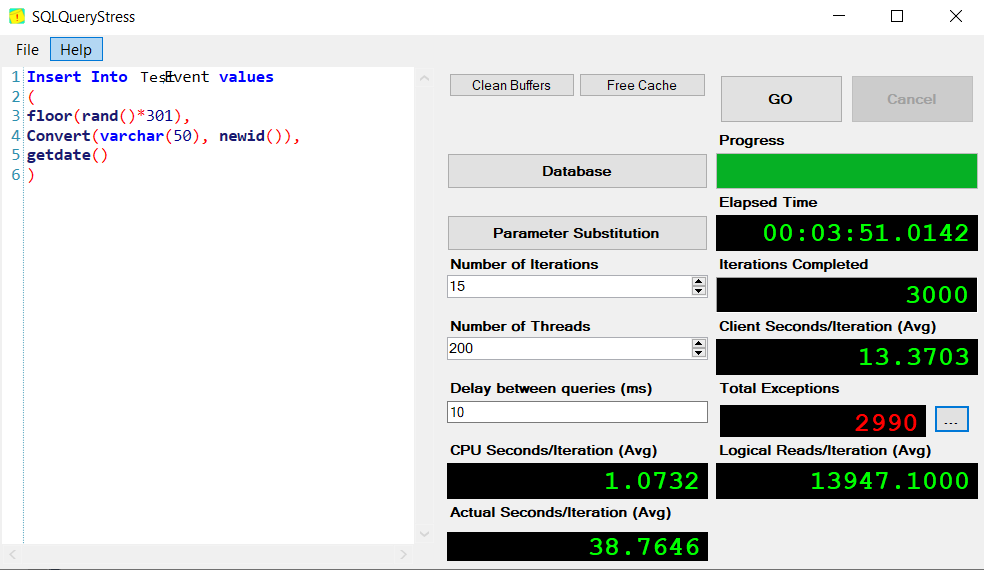
Eeeugughgh. Of the 3000 inserts, 2990 raised exceptions. All deadlocks. Performance suffered significantly as well, with this process taking almost 4 minutes to run.

The logs are full of this:
Transaction (Process ID 73) was deadlocked on lock | communication buffer | generic waitable object resources with another process and has been chosen as the deadlock victim. Rerun the transaction.
Trying the Trigger Again with Added Index
But wait! We are doing a lot of work in that trigger on the TestNum by joining on that attribute to the inserted data. Even though there is no index on it. Maybe our trigger will work beautifully if we just add an index so that fewer page locks are required.
CREATEINDEX ix_testevent_testnum
ON dbo.TestEvent(TestNum)
I first tested this with a smaller load of 15 iterations and 10 threads, and that ran super well. However, when I scale it up to close to the expected load, we see the deadlocks return although the elapsed time is much improved.
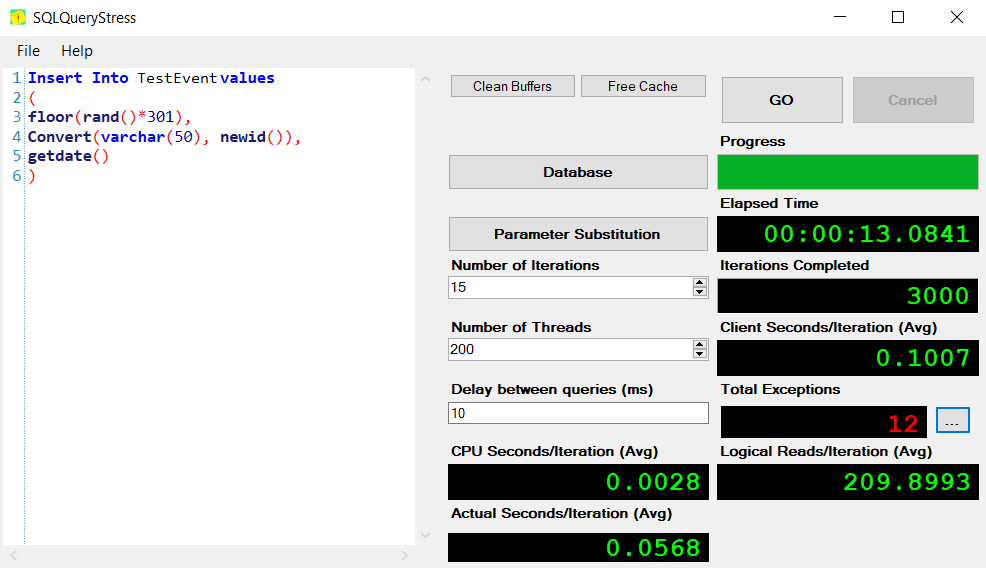
My conclusion? I was correct that a trigger was the wrong solution for managing rolling deletes against the table. I was impressed by how close we were able to get to the original performance though with proper indexing.
